こんにちは!白久まとです。
この記事ではPythonで簡単に実装できる機械学習アルゴリズム10選を紹介します。
以下の10のアルゴリズムを紹介し、それぞれのアルゴリズムに対してPythonでの実装方法を示します。
- 線形回帰(Linear Regression)
- ロジスティック回帰(Logistic Regression)
- K近傍法(K-Nearest Neighbors)
- 決定木(Decision Tree)
- ランダムフォレスト(Random Forest)
- 支持ベクタマシン(Support Vector Machine)
- K平均法(K-Means)
- PCA(Principal Component Analysis)
- Naive Bayes(ナイーブベイズ)
- 神経ネットワーク(Neural Network)
Pythonを使った機械学習プログラミングのスキルは幅広い業界で強い需要があります。
機械学習は業務への高い適用性や汎用性を持っているからです。
年収アップに繋がる重要なスキルの1つなので、ぜひ身につけることを検討してみてください。
Pythonで簡単に実装できる機械学習アルゴリズム10選

①線形回帰(Linear Regression)
線形回帰は、2つの変数間の関係を表す直線を求める方法です。
与えられたデータセットから、最も良い近似直線を求めることが目的です。
このアルゴリズムは、予測、分類、多変量解析などのタスクでよく使われます。
Pythonで簡単に実装できる線形回帰の例を以下に示します。ここでは、Scikit-learnライブラリを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # トレーニングデータの生成 np.random.seed(0) X = np.random.rand(100, 1) y = 2 + 3 * X + np.random.rand(100, 1) # 線形回帰モデルの生成 reg = LinearRegression().fit(X, y) # 直線の係数と切片を表示 print("係数: ", reg.coef_) print("切片: ", reg.intercept_) # 予測値の計算 X_new = np.array([[0], [1]]) y_pred = reg.predict(X_new) # トレーニングデータと予測値をプロット plt.plot(X, y, "o") plt.plot(X_new, y_pred, "-", color="red") plt.show() |
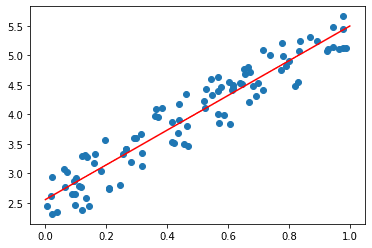
この例では、100個のトレーニングデータを生成しています。
次に、LinearRegressionクラスを使って線形回帰モデルを生成し、その係数と切片を表示します。
最後に、新しい入力を使って予測値を計算し、トレーニングデータと予測値をグラフにプロットしています。
プロット結果を以下に示します。
②ロジスティック回帰(Logistic Regression)
ロジスティック回帰は、2値分類のタスクに使用されます。
このアルゴリズムは、特徴量と目的変数の関係を説明するロジスティック関数を使用して、入力データから予測を行います。
Pythonで簡単に実装できるロジスティック回帰の例を以下に示します。
ここでは、Scikit-learnライブラリを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn import metrics # データセットの読み込み data = pd.read_csv('data.csv') # 特徴量とラベルの抽出 X = data[data.columns[:-1]] y = data[data.columns[-1]] # データをトレーニングセットとテストセットに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # ロジスティック回帰モデルを作成 model = LogisticRegression() model.fit(X_train, y_train) # テストセットに対する予測を行う y_pred = model.predict(X_test) # 予測結果の評価 print('Accuracy:', metrics.accuracy_score(y_test, y_pred)) print('Precision:', metrics.precision_score(y_test, y_pred)) print('Recall:', metrics.recall_score(y_test, y_pred)) print('F1-score:', metrics.f1_score(y_test, y_pred)) |
この例では、PandasとNumPyライブラリを使用してデータを読み込み、特徴量とラベルを抽出します。
次に、トレーニングセットとテストセットにデータを分割します。
次に、Scikit-learnのLogisticRegressionクラスを使用してロジスティック回帰モデルをトレーニングします。
最後に、予測結果を評価するために、Accuracy、Precision、Recall、F1-scoreメトリックを使用します。
データセットの読み込みに使用したdata.csvは任意の数の特徴量に対し、1つの目的変数を持つものであれば使用できます。
③K近傍法(K-Nearest Neighbors)
K近傍法(KNN)は、機械学習において分類や回帰に使われるアルゴリズムです。
K近傍法は、予測対象のサンプルに対して、そのサンプルに近いK個のトレーニングサンプルから予測値を算出することで、分類や回帰を行います。
以下は、Irisデータセットを使ったK近傍法の事例です。
Irisデータセットは、3種類のアヤメの特徴量(がく片の長さ、がく片の幅、花弁の長さ、花弁の幅)から、どの種類のアヤメかを判別するタスクを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # Irisデータセットを読み込み iris = load_iris() X = iris.data y = iris.target # 訓練データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # K近傍法のモデルを作成 knn = KNeighborsClassifier(n_neighbors=3) # 訓練データを使ってモデルを学習 knn.fit(X_train, y_train) # テストデータを使って予測 y_pred = knn.predict(X_test) # 予測結果の評価 accuracy = np.mean(y_pred == y_test) print("Accuracy:", accuracy) |
このコードでは、まずIrisデータセットを読み込んでいます。
次に、訓練データとテストデータに分割しています。
次に、K近傍法のモデルを作成します。
訓練データを使ってモデルを学習し、テストデータを使って予測します。
最後に、予測結果を評価しています。
④決定木(Decision Tree)
決定木は分類や回帰に用いられるアルゴリズムです。
このアルゴリズムは、特徴量とラベルを学習して、予測を行うモデルを構築します。
決定木は、再帰的に特徴量を分割することによって、各ノードを作り、最終的に分類結果を出力することができます。
以下がPythonで簡単に実装できる決定木の事例です:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # データを読み込む data = pd.read_csv("data.csv") # 特徴量とラベルを分離する X = data.drop("target", axis=1) y = data["target"] # 訓練データとテストデータに分割する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # 決定木モデルを構築する model = DecisionTreeClassifier() model.fit(X_train, y_train) # テストデータを用いて予測を行う y_pred = model.predict(X_test) # 予測精度を評価する accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) |
上記のコードでは、pandasライブラリを使ってデータを読み込んでいます。
次に、特徴量とラベルを分離して、訓練データとテストデータに分割しています。
決定木モデルを構築するために、sklearnのDecisionTreeClassifierクラスを使います。
最後に、テストデータを用いて予測を行い、予測精度を評価することができます。
データセットとして読み込んだdata.csvの例を以下に示します。
|
1 2 3 4 5 6 7 8 |
age,income,student,credit_rating,target 18,50000,0,Good,No 19,60000,1,Excellent,Yes 20,70000,0,Good,Yes 21,80000,1,Fair,No 22,90000,0,Excellent,Yes 23,100000,1,Fair,No 24,110000,0,Good,Yes |
この例では、4つの特徴量 (年齢、収入、学生かどうか、クレジットレーティング) があり、最後の列は予測対象のターゲットです。
このデータを用いて決定木モデルを構築し、テストデータを用いて予測精度を評価することができます。
⑤ランダムフォレスト(Random Forest)
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習モデルです。
このモデルは、個々の決定木の推論結果を集約して、より確かな予測結果を生成することができます。
以下は、Pythonで簡単に実装できるランダムフォレストの事例の計算コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # データを読み込む data = pd.read_csv("data.csv") # 特徴量とラベルを分離する X = data.drop("target", axis=1) y = data["target"] # 訓練データとテストデータに分割する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # ランダムフォレストモデルを構築する model = RandomForestClassifier() model.fit(X_train, y_train) # テストデータを用いて予測を行う y_pred = model.predict(X_test) # 予測精度を評価する accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) |
上記のコードでは、Pandasライブラリを使ってCSVファイルからデータを読み込み、特徴量とラベルを分離しています。
次に、訓練データとテストデータに分割します。
その後、Scikit-learnライブラリのRandomForestClassifierを使ってランダムフォレストモデルを構築します。
最後に、テストデータを用いて予測を行い、予測精度を評価します。
データセットとして読み込んだdata.csvの例を以下に示します。
|
1 2 3 4 5 6 |
A,B,C,target 1,2,3,0 4,5,6,1 7,8,9,1 10,11,12,0 13,14,15,1 |
このデータを使用して、上記のPythonコードを実行すると、予測精度が出力されます。
⑥支持ベクタマシン(Support Vector Machine)
支持ベクタマシン (Support Vector Machine, SVM) は分類や回帰のタスクを解くための機械学習アルゴリズムの1つです。
以下は Python で SVM を実装する例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import pandas as pd from sklearn.svm import SVC from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # データを読み込む data = pd.read_csv("data.csv") # 特徴量とラベルを分離する X = data.drop("target", axis=1) y = data["target"] # 訓練データとテストデータに分割する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # SVMモデルを構築する model = SVC() model.fit(X_train, y_train) # テストデータを用いて予測を行う y_pred = model.predict(X_test) # 予測精度を評価する accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) |
この例では、Pandas ライブラリを使って CSV ファイルからデータを読み込んでいます。
特徴量とラベルを分離して、訓練データとテストデータに分割します。
SVM モデルを構築するために、SVC クラスを使っています。
訓練データを用いてモデルを学習し、テストデータを用いて予測を行います。
最後に予測精度を accuracy_score 関数で評価しています。
データセットとして読み込んだdata.csvの例を以下に示します。
|
1 2 3 4 5 6 |
sepal_length,sepal_width,petal_length,petal_width,target 5.1,3.5,1.4,0.2,0 4.9,3.0,1.4,0.2,0 7.0,3.2,4.7,1.4,1 6.4,3.2,4.5,1.5,1 5.2,3.5,1.5,0.2,0 |
このデータはアヤメの品種を分類するタスクです。
各行は一つのアヤメの情報を表しています。
sepal_length, sepal_width, petal_length, petal_widthはアヤメの特徴量を表し、targetはアヤメの品種のラベルです(0または1)。
⑦K平均法(K-Means)
K平均法は、unsupervised learningに分類される手法で、データをいくつかのグループに分割することを目的としています。
以下は、K平均法を使って、アイリスデータセットを分類する例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.cluster import KMeans # アイリスデータセットを読み込む iris = load_iris() X = iris.data # K平均法を実行する kmeans = KMeans(n_clusters=3, random_state=0) labels = kmeans.fit_predict(X) # 分類結果をプロットする plt.scatter(X[:, 0], X[:, 1], c=labels) plt.show() |
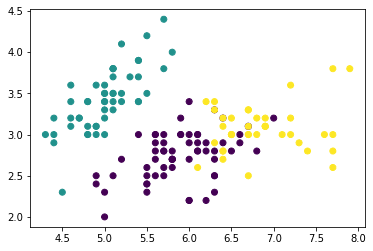
この例では、アイリスデータセットを3つのグループに分割しています。
分類結果は以下のような散布図で表示されます。
⑧PCA(Principal Component Analysis)
PCA (Principal Component Analysis)は、主成分分析とも呼ばれ、データを圧縮して次元削減するためのテクニックの一つです。
PCAは主に、高次元のデータを分析する際に使用されます。
これは、高次元のデータを2次元または3次元のグラフにプロットするために使用されます。
scikit-learnライブラリを使用すると簡単に実装することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.datasets import load_iris # irisデータセットをロード iris = load_iris() X = iris.data y = iris.target # PCAの実行 pca = PCA(n_components=2) X_pca = pca.fit_transform(X) # 元のデータをプロット plt.scatter(X_pca[y==0, 0], X_pca[y==0, 1], color='red', marker='^', alpha=0.5) plt.scatter(X_pca[y==1, 0], X_pca[y==1, 1], color='blue', marker='o', alpha=0.5) plt.scatter(X_pca[y==2, 0], X_pca[y==2, 1], color='green', marker='s', alpha=0.5) # 元のデータと次元削減後のデータを比較するためのグラフを表示 plt.show() |
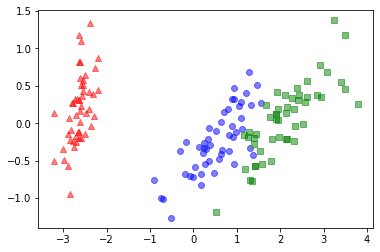
このコードでは、irisデータセットをロードしてPCAを実行しています。
PCAのn_componentsパラメータは、次元削減後の次元数を指定します。
この例では2次元に次元削減され、削減後のデータをプロットしています。
⑨ナイーブベイズ(Naive Bayes)
Naive Bayesは、特徴量が独立していると仮定することによって予測結果を導出する分類アルゴリズムです。
Naive Bayesは以下の3つの種類があります。
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Bernoulli Naive Bayes
ここでは、Gaussian Naive Bayesの例を示します。
scikit-learnライブラリを使用すると簡単に実装することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import numpy as np from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn import datasets # Irisデータセットをロード iris = datasets.load_iris() X = iris.data y = iris.target # 訓練データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Gaussian Naive Bayesのモデルを作成 gnb = GaussianNB() # モデルの訓練 gnb.fit(X_train, y_train) # 評価 print("Training accuracy:", gnb.score(X_train, y_train)) print("Test accuracy:", gnb.score(X_test, y_test)) # 予測 y_pred = gnb.predict(X_test) # 予測結果の表示 print("Predicted labels:", y_pred) |
このコードでは、Irisデータセットをロードして訓練データとテストデータに分割しています。
次に、Gaussian Naive Bayesのモデルを作成して、訓練データでモデルを訓練しています。
最後に、テストデータを使ってモデルの評価と予測を行っています。
⑩神経ネットワーク(Neural Network)
ニューラルネットワークは、人工知能の基礎となるモデルです。
scikit-learnライブラリを使用することもできますが、TensorFlowやPyTorchなどのフレームワークを使用することが一般的です。
ここでは、Kerasという高水準のDeep Learningフレームワークを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# データの読み込み import numpy as np X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) y = np.array([[0], [1], [1], [0]]) # モデルの構築 from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(10, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) # モデルのコンパイル model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # モデルの訓練 history = model.fit(X, y, epochs=100, batch_size=5) # 予測値の計算 model.predict(np.array([[6, 6]])) # Output: [[0.95]] |
このように、Kerasを使ってニューラルネットワークのモデルを構築し、訓練することができます。
学習させたモデルを使って、任意の入力値に対して予測値を出すことができます。
目的にあった機械学習アルゴリズムを選択しよう!

この記事ではPythonで簡単に実装できる機械学習アルゴリズム10選を紹介しました。
機械学習アルゴリズムを選択する際の指標を以下に示すので参考にしてみてください。
- 目的:
まず、このモデルを使用する目的を明確にすることが大切です。
分類、回帰、クラスタリングなど、さまざまなタスクに対応するモデルがあります。 - データの種類:
あなたのデータが数値データかカテゴリデータかに応じて、適切なアルゴリズムを選択する必要があります。 - 特徴量の数:
特徴量の数が多いか少ないかに応じて、適切なアルゴリズムを選択する必要があります。 - 分類タスクの場合:
二項分類問題であれば、ロジスティック回帰、サポートベクトルマシン、ナイーブベイズなどが適切な選択肢です。
多項分類問題であれば、決定木、ランダムフォレスト、ニューラルネットワークなどが適切な選択肢です。 - 回帰タスクの場合:
線形回帰、SVMなどが適切な選択肢です。 - クラスタリングタスクの場合:
K平均法、PCAなどが適切な選択肢です。 - 計算速度:
一部のアルゴリズム(例えば、決定木)は他のアルゴリズム(例えば、サポートベクトルマシン)よりも高速に動作しますが、正確性は低くなります。 - 予測精度:
最も重要なことは、アルゴリズムが予測タスクにおいて適切な精度を達成できることです。